| HPC Cluster | Cloud Platform | |
|---|---|---|
| Problem | A client operating under stringent confidentiality constraints needed to process billions of records and run large-scale simulations. Cloud environments were not permissible due to regulatory restrictions and desktop-based tools could not handle the computational load. | A client needed to analyze over ten petabytes of raw, log-level event data—consisting of billions of individual time-stamped records that log every user or system action—to understand behavior patterns. Existing tools could not ingest or transform the data without timing out or resorting to coarse sampling, making it difficult to analyze the data at a level of granularity best suited to model the economic dynamics relevant to the question at hand. |
| Solution | Analysis Group deployed the workload on our secure HPC cluster, distributing tasks across hundreds of CPU cores through automated job scheduling—the process of queuing and distributing tasks across cluster resources. | Analysis Group used a distributed Spark compute environment built on Databricks to parallelize ingestion and transformation across thousands of structured data files. Clusters were created on demand based on analysts’ availability and workload needs, allowing processing to scale seamlessly with the project. The Spark processing model abstracted away the complexity of parallelization so that analysts could write code in familiar languages like Python, R, or SQL. |
| Impact | This approach enabled complex time-series models, simulations, and entity resolution pipelines (processes that identify and link records referring to the same real-world entity across different datasets) to run at massive scale. As a result, model runtimes dropped from days to hours while fully meeting the client’s data-handling requirements and preserving analytical detail. | Ingestion and preparation time was reduced from weeks to days, enabling teams to run analytics and machine learning directly on the full dataset and transform overwhelming volumes of raw logs into streamlined, searchable, and queryable assets ready for economic analysis. |
In today’s digital economy, data are being generated at unprecedented speed and scale, from financial transactions and Internet of Things sensors to digital advertising and application logs. The rapid adoption of generative AI has only accelerated this growth, as organizations increasingly produce, capture, process, and interact with massive volumes of structured and unstructured data in real time. For context, a single terabyte of data can store more than 1,000 copies of the full Encyclopedia Britannica. Multiply that by 1,000 and you reach a petabyte—the scale of data at which many of Analysis Group’s clients operate.

At this magnitude, traditional approaches to data management, analysis, and decision making can struggle to keep pace with the volume, velocity, and complexity of the data. Analysis Group’s ability to build and operate end-to-end environments that process and analyze petabyte-scale data across multiple sources can deliver insights in hours or days rather than months. This is not just a technical advantage — it meaningfully influences how timely, defensible decisions are made.
The Problem: Scale, Speed, and Complexity
As datasets grow from terabytes to petabytes, the primary challenges shift from analysis to execution. At this scale, constraints around performance, infrastructure, and cost begin to shape what analyses are feasible and how reliable their results can be.
Why Data Formats Matter
These challenges are amplified by the reality that large-scale datasets take many forms. Behind every analysis lies a mix of storage formats, compression schemes, and data structures that can either accelerate or hinder performance. Making big data “work” requires not only computational power, but the ability to efficiently read, write, transform, and query information across diverse formats. At Analysis Group, we handle the full spectrum of modern data types, including columnar files such as Parquet or ORC, row-based formats such as CSV or JSON, compressed archives using gzip or Zstandard, and semi-structured logs and event streams.

Columnar formats like Parquet are well-suited for large-scale analytics because they compress efficiently and allow analytical systems to read only the data that matter, making it feasible to scan and analyze billions of rows quickly. Less optimized formats such as raw CSVs or multi-terabyte JSON logs can dramatically slow processing if handled incorrectly. At this scale, the ability to efficiently ingest, convert, repartition (redistribute), and restructure data is as critical as the raw compute power needed to process the data.
A naïve approach to long analysis pipelines is to let them run sequentially end-to-end. In practice, especially when working with new data, this method can lead to recurring delays and missed windows for decision making. Analysts are forced to choose between waiting for results or simplifying the analysis in ways that compromise accuracy. This highlights a deeper issue: large-scale analytics failures are rarely caused by data volume alone, but rather by the interaction of scale, infrastructure, and data design.
Our Solution: High-Performance, Scalable Infrastructure
At Analysis Group, we have invested in two complementary approaches to handle large-scale analytics without compromising performance, reliability, or data privacy. Think of our infrastructure as a team of powerful machines working in parallel, each tackling a different part of a problem. This parallelization allows us to process massive datasets, run complex simulations, and execute sophisticated models far faster than any single machine could manage while maintaining flexibility, security, and control.
AI can also help earlier in the process by assisting with data intake and triage. By identifying which portions of a large dataset are most likely to be relevant to the question at hand, we can reduce time and cost spent importing, processing, and analyzing materials that ultimately are not needed. Our in-house compute resources, together with our broader AI service options, give us the flexibility to leverage AI for data intake in the environment that best fits our clients’ needs. We will explore these AI workflows and infrastructure in future blog posts.
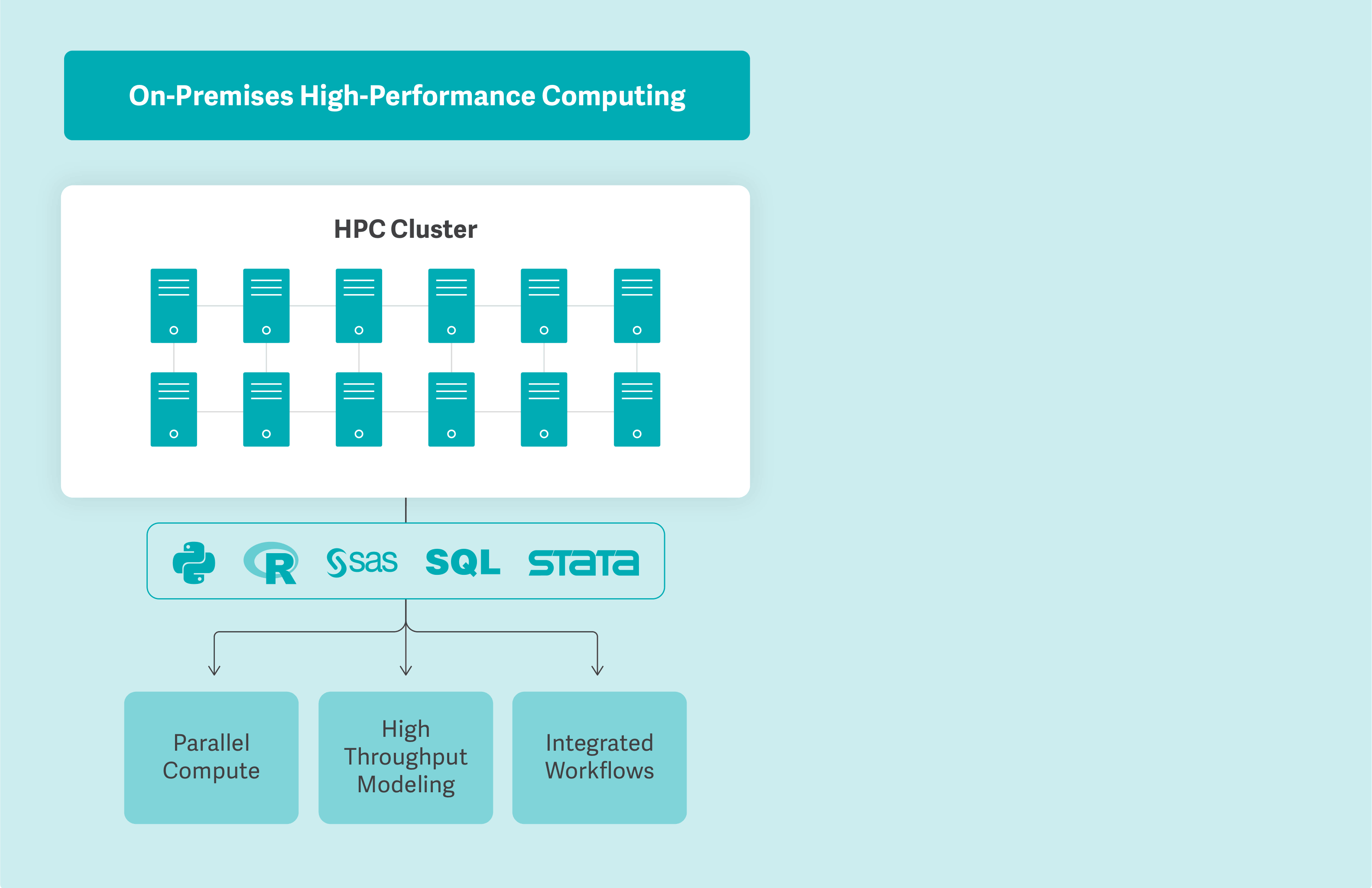
Our on-premises high-performance computing (HPC) cluster supports tightly controlled, large-scale, high-volume analytical workloads, and is designed for analyses that require secure access to proprietary or regulated data where both speed and confidentiality are essential.
It consists of multiple interconnected compute nodes that work in parallel, allowing workloads to be distributed across dedicated resources rather than relying on a single machine.
The environment provides efficient, out-of-the-box support for widely used programming languages such as Python, R, SQL, Stata, and SAS, while remaining flexible enough to accommodate virtually any programming language or framework as needed.
Direct integrations with our analytic toolchains and automated workflows allow teams to immediately scale for data preparation and large-scale modeling, making high-performance computing both fast and flexible.
For highly elastic workloads (those with computing or storage needs that can rapidly scale up or down), we deploy fully managed cloud environments that can provision compute in minutes and scale elastically to petabyte-scale datasets.
We work flexibly across cloud providers and platforms such as Databricks (Spark and Lakehouse) for distributed data processing and machine learning modeling, Amazon Redshift for high-performance SQL-based analytics, and Google BigQuery for serverless, instantly scalable querying. Each environment is selected based on the analytical problem and the client’s preferences, ensuring speed, security, and cost effectiveness.
These “big data environments-as-a-service” provide preconfigured toolchains and libraries, automated cluster management, reproducible analytics, and on-demand elasticity—with cost control.
Together, these complementary approaches allow us to select the right platform for each problem, balancing speed, security, and scalability.




Spinning up secure cloud environments that support client-specific compliance requirements is both rapid and standardized, allowing teams to establish isolated infrastructure within minutes while maintaining robust security boundaries and access controls. Even within shared cloud ecosystems, data and workloads are logically isolated across projects, supporting effective data protection and governance without sacrificing flexibility or scalability. At the same time, cloud platforms differ fundamentally from on-premises HPC environments in terms of control, data governance, and infrastructure ownership. Our HPC architecture is particularly well-suited for highly sensitive, proprietary, or regulated data, where security and compliance requirements are critical. It also provides greater predictability in performance and cost for sustained, compute-intensive workloads. As organizations increasingly prioritize data control, privacy, and cost discipline, our complementary model combines secure, scalable cloud environments with on-premises HPC infrastructure to position us to effectively support large-scale analytics now and going forward.
Examples
Associated Contributors
For more information about the tools or technology in this post, please reach out to: Mihran Yenikomshian (Managing Principal, Boston); Christopher Borek (Managing Principal, DC); Jimmy Royer (Principal, Montreal); Shogo Hamasaki (Vice President, DC); Riccardo Marchingiglio (Vice President, DC); Peter Jones (Vice President, San Francisco); Max Leroux (Director of Data Science, Montreal).
Development for this work was supported by: Mehak Piplani (Senior Data Scientist, Boston); Yash Lalwani (Senior Data Scientist, Montreal); Chi Pham (Analyst, Boston).